单片机8085与8051的比较
一 前言
。由于8051与8085的指令动作很类似,而现行市面上比较容易取得的信息是8051,在经过8051的练习实作之后,我们将8085与8051做一比较整理,期望已经对8051了解的人,能够藉由此报告很快的对8085有所了解。
二 一般硬件结构
Intel公司于1976年首先发展出MCS-48,它是一个八位CPU,内部配有最多4K
bytes的程序内存(即ROM或EPROM),和最多256 bytes的数据存储器(RAM),以及一个8
bit的定时器和27条I/O。到了1980年的时候,Intel又根据MCS-48的架构改良而发展出MCS-51,这个单芯片仍使用8位CPU,但程序内存的空间可达64
Kbytes,内部有256 bytes的数据存储器(RAM)和两个16
bit定时器和32条I/O。以下是一般我们常见的MCS-51的内部结构如下:
| 内部结
构
编号 |
内部存储器 |
输入/输出 |
计时/计数器 |
|
RAM |
ROM |
EPROM |
I/O |
16位 |
|
8031 |
128byte |
0 |
0 |
32 pins |
2个 |
|
8051 |
128byte |
4K byte |
0 |
32 pins |
2个 |
|
8751 |
128byte |
0 |
4K byte |
32 pins |
2个 |
|
89C51 |
128byte |
0 |
4K byte |
32 pins |
2个 |
|
8032 |
256byte |
0 |
0 |
32 pins |
3个 |
|
8052 |
256byte |
8K byte |
0 |
32 pins |
3个 |
|
8752 |
256byte |
0 |
8K byte |
32 pins |
3个 |
|
89C52 |
256byte |
0 |
8K byte |
32 pins |
3个 |
表1. MCS-51系列常用编号之内部结构
早在1971年12月,Intel公司就设计了第一部8位微处理机8008,它是利用标准型半导体内存(ROM和RAM)以及TTL集成电路来组成一个系统,那是采用P通道MOS处理技术的一般用途处理机,以18
pins双引线集成电路包装(DIP)。到了1973/1974年,Intel公司在8008的基础上利用N通道MOS处理技术设计出8080微处理机。后来设计8080微处理机的工程师分成了两组,一组仍留在Intel公司内改良8080而设计出8085;另一组脱离Intel公司自组成Zilog公司而设计出Z80微处理机。
8085没有内部的数据存储器或程序内存,但只要利用8155/8156(RAM)或8355(ROM)就可以组成一部基本的微电脑系统。8155和8156都是含有256
bytes 内存,两个位输入/输出端口和一个6位输入/输出端口,以及一个14位可做程序规划的计时/计数器。它们都是采用40 pins
双引线集成电路包装,工作电压+5V。8155和8156的不同点在于选择芯片的逻辑准位。也就是在芯片致能接脚(Chip
Enable),8155要求逻辑准位”0”,8156要求逻辑准位”1”,除此之外两个装置是一样的。而8355是含有2K
bytes的只读存储器,两个8位可直接做程序规划的输入/输出埠,也是采用40 pins 双引线集成电路包装,工作电压+5V。
(一) 基本结构与功能
中央处理单元(CPU)
8051的CPU可以执行二进制的加,减,乘,除和BCD码的加法,但无法执行BCD减法。8051除了有Byte逻辑运算能力外还提供所谓单位元逻辑运算能力,称为布尔运算器。
8085除了能够做BCD算术,也能处理16位数据的寻址计算。它和8051一样使用多任务地址/数据通径法。以下是8051与8085的俯视图:
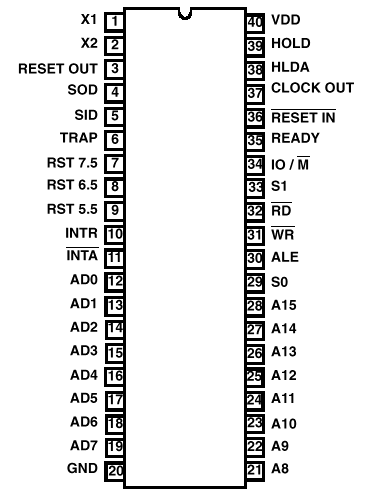
图1. 8051接脚图
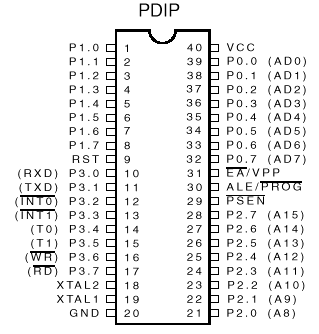
图2. 8085接脚图
(二) 时脉产生器
一般的单芯片都留两支接脚与外接的石英晶体连接,以决定振荡频率,所产生的频率决定了CPU执行程序的快慢。8051最高(晶体)工作频率为12MHz,1个机械周期为12个工作时脉,所以机械周期等于一微秒(1μs)。标准的8085所采用的晶体(工作频率)最高为6.25MHz,这是双倍于内部时脉频率。8085A-2可采用高达10MHz的晶体。以下是8085的时脉周期时间:
表2. 8085的时脉周期时间
|
符号 |
说明 |
8085AH |
8085AH-2 |
8085AH-1 |
单位 |
|
最小 |
最大 |
最小 |
最大 |
最小 |
最大 |
|
tCYC |
时脉周期时间 |
320 |
2000 |
200 |
2000 |
167 |
2000 |
ns |
以下是data sheet所提供的时脉线路:
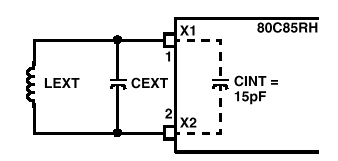
图3-a. 石英晶体驱动时脉线路
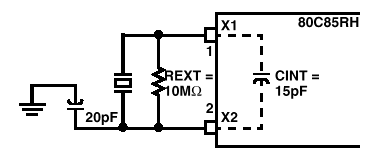
图3-b. LC调变驱动时脉线路
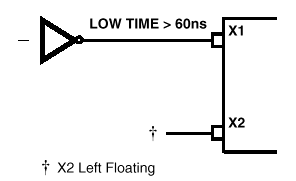
图3-c. RC驱动时脉线路
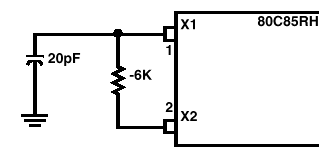
图3-d. 外部输入频率0~4MHz驱动时脉线路
(三) 中断控制器
对于8051内部外围装置(Time0,Time1和UART)而言,其中断要求信号已在内部接到8051的中断系统,因此不须再行连接,而8051外部也提供了两条中断要求(INT0和INT1)以提供外部扩接的外围的外围装置对8051提出中断要求。8051的INT0与INT1相当于8085的INTR。8085没有像8051的内部中断。
8051可以接受5个(2个外部,3个内部)中断要求信号,若5个中断要求同时被检知,8051会根据内部的中断优先权缓存器来决定对谁先服务。透过规划这个中断优先权缓存器,这5个中断的优先权顺序就可以由使用者加以安排。但若有两个具有相同优先权的中断请求”同时”发生,则8051会按照表4
之中断优先级来决定其执行中断子程序的顺序。而8085的中断优先级由高至低依次为TRAP, RST7.5, RST6.5,
RST5.5,INTR。
8051中断优先权的规划只分成两个层次,即高优先权和低优先权,其设定的方法是规划IP缓存器里各个中断源的优先权控制位,被设为1的就到高优先权层,设为0的就到低优先权层。
8051的中断结构是属于二层式的中断,即主程序被其中一个中断源中断后跳至这个中断子程序执行,若在此刻有另一个较高优先权层的中断要求在此时提出,则这个较低优先权的中断子程序会被中断,如此中断再被中断称为二层式中断。其中断的原则是相同优先权层里的中断源不能互相中断,所以高优先权的子程序是能再被中断。
中断的型态有两种类别,即所谓的中断要求(IRQ)和不可屏蔽式中断(NMI),所谓NMI是当外围对NMI提出中断要求时,微处理机会无条件地接收这个中断要求。而IRQ则是当外围对IRQ提出中断要求时,微处理机不一定去理会这个中断要求,要看这个中断要求是否在先前已被允许状态。至于允不允许IRQ的中断?是由8051内部提供的中断允许(
或称致能)缓存器(IE),这个缓存器中的前5个位控制了8051的5个中断源是否被允许,而这些位可透过软件加以设定。因此8051的中断型态是属于IRQ的型态。(8051不提供NMI)。而8085除了能提供IRQ之外,它还能提供NMI,那就是TRAP中断。
8085A提供5个硬件中断输入,可划分成下面三组:
1. INTR
2. RST7.5
RST7.6
RST5.5
3. TRAP
INTR中断输入是可罩除的,利用指令EI和DI可使INTR中断致能或除能。
RST5.5,RST6.5,RST7.5硬件中断在功能上与INTR有所不同.它们可经由指令SIM罩除。SIM指令借累加器里的值清除或设置相应的罩除旗标来使这些中断致能或除能。而利用指令RIM可以读到先前设置的中断罩除状况。利用EI和DI指令也可以分别使RST5.5,RST6.5,RST7.5致能或除能。INTR,RST5.5和RST6.5是准位触发,RST7.5是边缘触发。
TRAP中断是无法罩除,也不接受任何中断致能或除能的影响。TRAP输入接脚上的正向边缘触发8085硬件中断顺序,但是此边缘触发脉动必须维持于高状态直至内部认可为止。所有中断的取样侦测都发生在中断输入被激化的那一指令周期结束前一个时脉周期的CLK下降边缘。
当8051接受了中断要求信号后就会跳至某个固定的地址去执行这里的中断服务程序,这些起始的位置称为中断向量。8085亦是如此,以下分别是8051与8085的中断向量表:

表4. 8051中断向量表
|
SOURCE |
POLLING PRIORITY |
REQUEST BITS |
VECTOR ADDRESS |
|
INT0 |
1 |
IE0 |
03H |
|
Timer0 |
2 |
TF0 |
0BH |
|
INT1 |
3 |
IE1 |
13H |
|
Timer1 |
4 |
TF1 |
1BH |
|
UART |
5 |
RI,TI |
23H |
(四) 串行通信接口
MCS-51内部提供了一组标准外围串行接口,称为UART。UART是一个全双工串行接口,共有四种工作模式:MODE0~MODE3。基本上数据位都是8个bit,因为工作模式的不同,传输的格式有不同的bit数:8,10,11。当每笔数据传送或接收完毕,TI或RI就会被设为1。8085是利用外部的通信接口芯片8251A
USART来作串行数据传输。8251A USART可以从微处理机那里接受并列的数据,将之转换成并列的数据。同时,也可以接收串行资料,将之转换为并列的资料传送给微处理机。它的数据缓冲器也是8位,但是它无法像8051的UART做到全双工。8051的接脚RXD与TXD分别负责串行数据的接收与传送。8251A的接脚RXD与TXD分别负责串行数据的接收与传送。8085是利用接脚SID与SOD作为串行数据输入与输出。当指令RIM执行时,SID接脚上的状态信息就被读入累加器的位7中;而当SIM指令执行时,累加器位7的值就经由一个内部正反器SOD接脚上输出给串行输入/输出埠。此时累加器位6被设置为1。SID可做一般目的的试验输入,而SOD可用做一个1位控制输出。
(五) 周期时间与基本操作
(i)多任务通径之周期时间
任何8085程序的执行都是由一系列的READ和WRITE操作组成。这些操作在8085和特定的内存或输入/输出位置间转移一字节数据。8085执行的每个指令由一到五个顺序机械周期组成,而每个机械周期由三个到六个时脉周期组成,至少要有三个时脉周期。对于相同的外部时脉而言,8085的内部工作时脉较快,但是8085需要较多的工作时脉来完成一个指令,所以在程序执行上8085比8051慢很多。以下分别是8085与8051的读取数据的时序图:
图4. 8085读取数据时序图
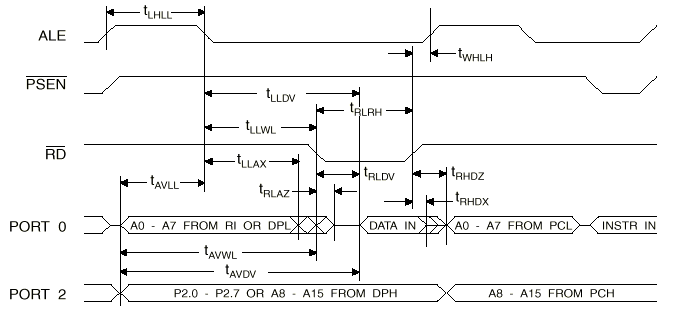
图5. 8051读取外部数据存储器时序图
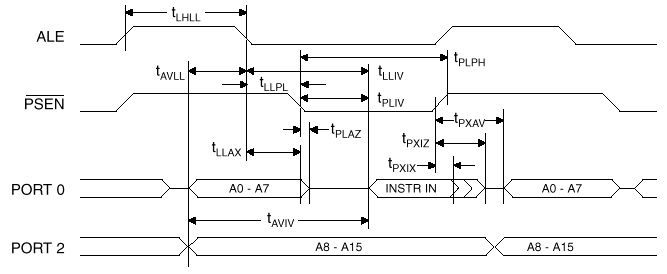
图6. 8051读取外部程序内存时序图
8085与8051有相同的8位三态双向时间多任务通道AD0-AD7来转移数据,这个信道也转移16位低位部的8位地址,而16位高位部的8位地址则由地址信道A8-A15来转移。8051每一只埠脚皆由闩锁(D型正反器;latch),输出驱动电路及输入缓冲器所组成。8085是利用数据信道状态线S0,S1来决定数据信道处于暂停-HALT(S0=0,S1=0),写-WRITE(S0=1,S1=0),读-READ(S0=0,S1=1),取出指令-FETCH(S0=S1=1)。8051与8085在对外部装置存取数据时,都是利用ALE接脚输出脉波的负缘来锁住(LATCH)由AD0-AD7
送出的低字节地址。因8051有内部程序内存,所以在对外部内存做存取时,必须利用PSEN接脚对外部程序内存致能。8051欲读取外部程序内存的内容时,PSEN会自动产生负脉波,8051读取内部程序内存或是数据存储器,是不会有此动作。以下是8051与8085对内存写入数据的时序图:
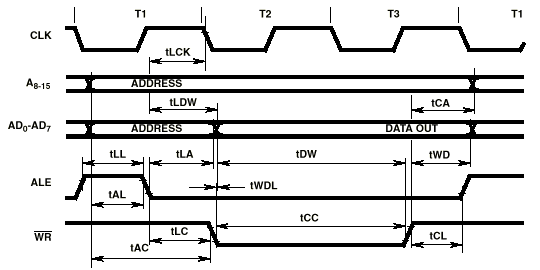
图7. 8085写入资料时序图
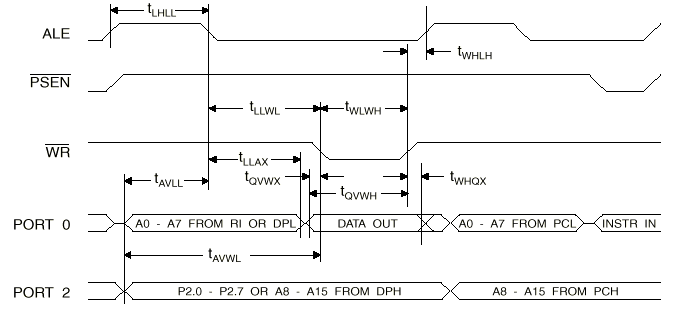
图8. 8051写入外部数据存储器时序图
(ii)状态转换顺序
一个指令的执行是由一系列机械周期所组成其性质和顺序是由在
第一机械周期M1内取出的操纵码来决定。所有指令周期都不能含有多过5个机械周期,每个机械周期可为七种不同的操作之一。这七种不同的机械周期由三条状态线(IO/M,S1,S0)和三条控制线(RD,WR,和INTA)的状态来决定。以下是8085的机械周期表:
表5. 8085机械周期表
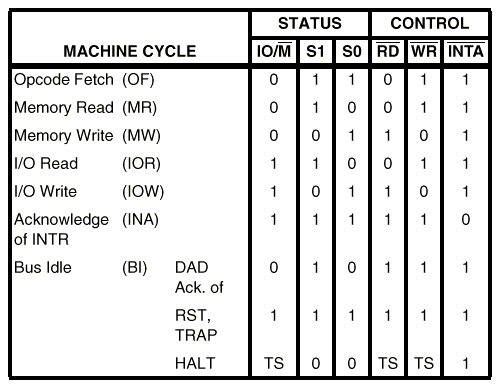
8085在每一机械周期的开始所做的第一件事是送出三个状况讯号IO/M,S1,S0
,这三个状况讯号定义即将发生的机械周期的操作类别。IO/M讯号认定机械周期为内存或输入/输出操作;S1状况讯号认定机械周期为读或写;SO和S1状况讯号一起认定读,写或操作码取出机械周期以及暂停状态。
因为AD0-AD7上的地址信息只有瞬息性,它必须被保存在特殊多任务通径组件,而8085就是利用ALE(Address
Latch Enable)来便利A0-A7的保存。8051亦是利用相同的方式保存数据。
大多数机械周期都含有三个T状态(即CLK输出周期),但取出操作码的第一机械周期M1例外,M1通常含有4或6个T状态。不过执行任何指令所需要的实际状态数目则由执行中的指令其指令周期内特定的机械周期和利用8085
READY和HOLD输入讯号插入每个机械周期内的WAIT和HOLD状态数目来决定。以下是8085系统基本的时序图:
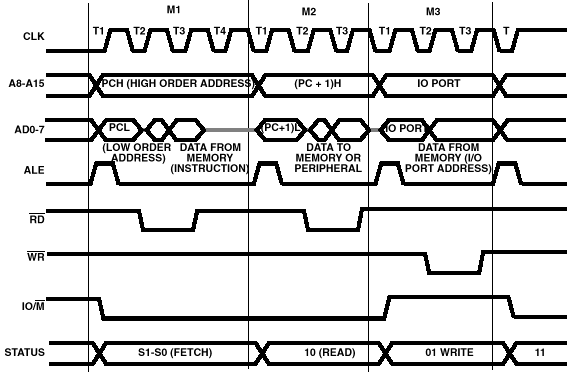
图9. 8085系统基本时序图
三 软件指令方面
由于8051的发展时间比8085晚,所以在指令上的有些功能会简化很多,而且会配合输入/输出端口的功能,增加指令的应用性。不过8051大部份的指令大都可对应到8085,虽然8085有些单一指令无法对应到8051,不过可藉由几个指令的组合来达成相同的动作。以下分别介绍8051与8085的寻址模式与指令间的比较:
(一) 寻址模式(Addressing Mode)
(i) 8051的寻址法可分为下列5种:
1. 直接寻址法 (direct addressing):
在指令中直接指定操作数所在的地址,例如:
MOV A,7F ;把地址7FH的内容放入累加器A
直接寻址法用在内部存储器00H~7FH特殊功能缓存器中及位寻址范围内。8085也有直接寻址法,只不过8085没有内部存储器,所指定的地址都是外部内存,不像8051在指令上还分出内部存储器与外部内存的用法。8051有些指令动作很像8085的缓存器寻址法。8085所有程控的指令都是直接寻址法,而8051就不全是直接寻址法。
2. 间接寻址法 (indirect addressing):
在指令中不直接指定操作数的地址,而是把操作数的指标(pointer),8051内部具有这种指针功能的缓存器有R0,R1,SP,DPTR。间接寻址法的前置符号为”@”。R0,R1,SP是8位缓存器,DPTR是16位缓存器。R0,R1是两个性质完全相同的指标,可以用来寻址内部数据存储器和外部扩充数据存储器,例如:
MOV R0, #30H ;
MOV A, @R0 ;间接寻址法取得内部RAM地址30H的内容
MOVX A, @R0 ;间接寻址法取得外部RAM地址30H的内容
SP缓存器是堆栈指针(Stack Pointer)。它是堆栈区存放或取 出数据的指位器,例如:(如果SP=30H)
PUSH 80H ;把地址80H的内容放在内存地址31H内
DPTR是用来寻址外部数据存储器和程序内存的专用指针,例如:
MOV DPTR, #23ABH ; 将外部数据存储器地址23ABH的内容拿到累
MOVX A, @DPTR ; 加器A
至于8051的B缓存器主要是用来做乘法和除法的运算,在乘法运算中用来存放乘数及运算结果的余数。但是不做乘除运算时,B缓存器也可以当做一般用途的缓存器来使用。而8085的B缓存器能配置成对BC以处理16位的数据。
此寻址法的动作和8085的缓存器间接寻址法相同。
3. 缓存器寻址法 (register addressing):
在8051内部RAM有四组缓存器库(R0~R7),至于要使用那一个缓存器库(bank)的缓存器,则取决于PSW缓存器里的RS0,RS1两个bit。
此寻址法的动作和8085的缓存器寻址法相同。
4. 立即寻址法 (immediate addressing):操作数是存放在指令码的后面,例如:
MOV A, #20H ;将一个常数20H放入累加器A
此寻址法的动作和8085相同。
5. 索引寻址法 (indexed addressing):
以一个基底缓存器的内容,再加上一个索引缓存器的内容,所得的值即是操作数所在的地址。8051只有程序内存的内容才具有索引寻址法,基底缓存器是DPTR或PC(程序计数器),索引缓存器则是累加器A。例如:
MOV A, #28H ;
MOV DPTR, #3501H ;
MOVC A, @A+DPTR ;取得程序内存地址3529H的内容到A
8085单一指令格式没有索引寻址法,但是8085可以利用几个指令的组合达成索引寻址法,得到和8051相同的效果(所需的指令时间自然也比较多):
LXI D, BASE ;将基地址(16位)移入缓存器D
MOV L, A ;将累加器的地址移入缓存器L
MVI H, 0 ;将累加器H的内容设为0
DAD D ;将累加器的地址与基地址相加
MOV A, M ;从内存取出相加后的地址内容加载累加器
(ii) 8085的寻址法可分为下列6种:
1. 直接寻址法 (direct addressing):
所有程控指令都采用直接寻址法。指令的第二和第三组元含有跳控的16位地址。
2. 缓存器间接寻址法 (register indirect addressing):
采用缓存器间接寻址法的指令所指定的缓存器对所储存的是内存的地址,该地址的内存位置含有待处理或运算所需要的资料。
3. 缓存器寻址法 (register addressing):
指令所指定的缓存器或缓存器对含有处理或运算所需要的数据。这些指令的一个操作元必须指定一般用途缓存器B,C,D,E,F,H,L之一,而累加器A为指令所暗示的操作元。如CMP
B是将累加器A和缓存器B的内容作比较。
4. 立即寻址法 (immediate addressing):
采用立即寻址法的指令本身含有待处理或运算的数据。此立即指令表示它们使用立即数据。这些指令通常于最后一字符以I来区别,如ADI,CPI,MVI等。
5. 内示寻址法 (implied addressing):
指令的功能暗示着指令本身所采用的寻址方法,例如:指令STC(设置进位旗标为1)暗示只处理进位旗标;而指令DAA(累加器十进制数调整)暗示只处理累加器。8051有一些指令也是此种寻址法,不过现在8051的书籍并没有强调。8085内示寻址法的指令有:
CMA,CMC,DAA,RAL,RAR,RIM,RLC,RRC,STC。
6. 混合寻址法 (combined addressing):
既应用立即寻址法,又采用缓存器间接寻址法。8051有一些指令也是此种寻址法,不过现在8051的书籍并没有强调。8085使用混合寻址法的指令格式有:
“ADC M”,”ADD M”,”ANA M”,”CALL address”,”CC address”,”CM
address”,”CNC address”,”CNZ address”,”CP address”,”CPE address”,”CPO
address”,”CZ address”,”MVI M,I8”.
(二) 指令集
以下我们将介绍8051与8085的指令集,以8051为主干逐一说明指令功能的对应关系,最后列表。我们可以根据表上所列的每个指令所需的工作时脉周期数,来算出每个指令执行所需的时间。8051的1个机械周期等于12个工作周期,但8085就不是那么规则,随着指令的不同,1个机械周期会有不同的工作周期数。因此要计算8085指令执行所需的时间,不能直接由机械周期数做判断。
(i) 8051的指令集
(1). 算术运算指令:
共有9种。其中8085不能对应到的指令有:”ADD A,address”,”ADDC a,address”,”SUBB
A,address”,”MUL AB”,”DIV AB”。
1. ADD A,<src-byte>:
缓存器累加:
ADD A,Rn (Rn有4个:R0~R3),动作:(A)←(A)+(Rn)此指令动作与8085之” ADD R
“(R有7个 : B,C,D,E,H,L,A)相同(动作:(A)←(A)+(R)),都只需要1个机械周期。
立即数据累加:
ADD A, #data ; 动作:(A)←(A)+#data
此指令动作与8085之” ADI I8 “,( I8
为8位立即数据)相同((A)←(A)+ I8
)。8051只需1个机械周期,但8085需2个机械周期。格式上的差别,
例如:(8051)
MOV A, #12H ;A=12H
ADD A, #34H ;A=12H+34H=46H
(8085)
MVI A, 12H ;A=12H
ADI A, 34H ;A=12H+34H=46H
直接字节累加:
ADD A,direct ;动作:(A)←(A)+(direct)
8051需要1个机械周期,而8085需要2个机械 周期。此指令动作与8085有部分相同,例如:
(8051) ADD A, B ;把缓存器B的内容加入累加 器A内
(8085) ADD B ;把缓存器B的内容加入累加器A内
但是若8051写成以下的格式,8085没有对应的指令写法:
ADD A, 25H ;把内部RAM地址25H的内容加入累加器A内
间接字节累加:
ADD A, @Ri (i=0~1) ;动作:(A)←(A)+((Ri))
此指令动作与8085之 ” ADD M
”(M为参考缓存器H和L的符号)有类似的地方。8051需要1个机械周期,8085类似动作的指令需要2个机械周期。写法的差别如下:
(8051)
MOV R1, #30 ;R1=30H
ADD A, @R1 ;把内部RAM地址30H的内容加入累加器
(8085)
LXI H, 100H ;将RAM地址100H的位置加载(H, L)缓存器中
ADD M ;把RAM地址100H的内容加入累加器中
8085有一特定的缓存器对16位加法指令是8051所没有的:
DAD RP ; 动作:(HL)←(HL)+(RP)
此指令只能加缓存器对B&C,D&E,H&L或SP的内容到H&L的内容中,若产生进位,此指令会设置进位旗标。例如:
设HL=034AH,BC=214CH
DAD B ;执行之后,HL=2496,C=0,BC和其它指标不变
2. ADDC A,<src-byte>:
缓存器与进位旗标累加:
ADDC A, Rn ;动作:(A)←(A)+(C)+(Rn)
此指令动作与8085之 “ ADC R ”相同,都只需要1个机械周期。
立即数据与进位旗标累加:
ADDC A, #data ; 动作:(A)←(A)+(C)+data
此指令动作与8085之 “ ACI I8 “ (动作:(A) ←(A)+(C)+ I8)
相同,8051只需要1个机械周期,8085需要2个周期。
直接字节与进位旗标累加:
ADDC A, direct ; 动作:(A)←(A)+(C)+(direct)
此指令动作与8085之” ADC R”有类似的功能,都只需要 1个机械周期。但8051以下的写法在8085中没有对应的写法:
ADDC A, 20H ;把进位旗标C的内容及内部RAM地址20H的内容加入累加器
间接字节与进位旗标累加:
ADDC A, @Ri ;动作: (A)←(A)+(C)+((Ri))
此指令动作与8085之” ADC M “ (动作: (A)←(A)+(C)+(M))相同,8051需要1个机械周期,8085须要2个机械周期。
3. SUBB A,<src-byte>:
累加器减缓存器再减进位旗标:
SUBB A, Rn ;动作: (A)←(A)-(C)-(Rn)
此指令动作与8085之 “ SBB R “相同,都只需要1个机械周期。
累加器减立即数据再减进位旗标:
SUBB A, #data ;动作: (A)←(A)-(C)-data
此指令动作与8085之 “ SBI I8 “相同(动作: (A)←(A)-(C)- I8
),8051需要1个机械周期,8085需要2个机械周期。
累加器减直接字节再减进位旗标:
SUBB A, direct ;动作: (A)←(A)-(C)-(direct)
此指令动作与8085之 “ SBB R “相似,都只需要1个机械周期,但以下的指令写法是8085没有的:
SUBB A, #22H ;累加器的内容减去内部RAM地址22H的内容再减去进位旗标的内容
SUBB A, P1 ;累加器的内容减去P1埠的内容再减去进位旗标的内容
累加器减间接字节再减进位旗标:
SUBB A, @Ri ;动作: (A)←(A)-(C)-((Ri))
此指令动作与8085之 ” SBB M “(动作: (A)←(A)-(C)-(M))
相同,8051只需1个机械周期,8085需要两个机械周期。
8085有两个减法运算的指令是8051所没有的分别是:
SUB R(或M) ;动作: (A)←(A)-(R)或(M)
机械周期(SUB R):1 ; (SUB M):2。
SUI I8 ;动作: (A)←(A)-(I8) ,机械周期:2。
它们与上述的8085指令的差别只在于在做减法运算时没有减掉进位旗标的内容。
4. INC <src-byte>:
累加器递加:
INC A ; 动作:(A)←(A)+1
此指令动作与8085之 “ INR A “相同,都只需要1个机械周期。
缓存器递加:
INC Rn ; 动作:(Rn)←(Rn)+1
此指令动作与8085之 “ INR R “相同,都只需要1个机械周期。8085的指令对于缓存器内容处理,有另一个指令是处理缓存器对的内含值—“
INX RP “ (动作:(RP)←(RP)+1,机械周期:1),不同于8051视为单一字节的处理,举例如下:
(8051)
MOV R5, #15H ;R5=15H
INC R5 ;R5=16H
(8085) 设缓存器对DE含有01FFH数值,那么执行
INX D ;执行之后,DE的值为0200H
INX E ;执行之后,DE的值为0100H,忽略了低位部组元所产生的进位
直接字节递加:
INC direct ; 动作:(direct)←(direct)+1
此指令动作与8085之 “ INR R “相同(动作:(R)←(R)+1),指定的字节内容可以在缓存器A,B,C,D,E,H和L之中,动作上都只需要1个机械周期,但以下的写法在8085是没有对应的写法:
(8051) INC 30H ;把内部RAM地址30H的内容加1。
间接字节递加:
INC @Ri ; 动作:((Ri))←((Ri))+1
此指令动作与8085之 “ INR M
“相同(动作:(M)←(M)+1),8051只需1个机械周期,8085却需要3个机械周期。
5. INC DPTR:将数据指针的内容加1,
INC DPTR ; 动作:(DPTR)←(DPTR)+1
此指令动作与8085之 “ INX SP
“相同,而且指令都不会影响任何旗标,8051需要2个机械周期,8085只需要1个机械周期。
6. DEC <src-byte>:
累加器递减:
DEC A ; 动作:(A)←(A)-1
此指令动作与8085之 “ DCR A “相同,都只需要1个机械周期。
缓存器递减:
DEC Rn ; 动作:(Rn)←(Rn)-1
此指令动作与8085之 “ DCR R “相同,都只需要1个机械周期,对进位期标没有影响,都只需要1个机械周期。8085的指令对于缓存器内容处理,有另一个指令是处理缓存器对的内含值—“
DCX RP “ (动作:(RP)←(RP)-1),DCX指令只能减少缓存器对B&C,D&E,H&L或SP的内容,它会把两个缓存器的内容当做单个16位值处理,所以会有借位的产生,例如:
(8051)
MOV R5, #15H ;R5=15H
DEC R5 ;R5=14H
(8085)
设缓存器对HL=9800H
DCX H ;执行之后,HL=97FFH
直接字节递减:
DEC direct ; 动作:(direct)←(direct)-1
此指令动作与8085之 “ DCR R “相同(动作:(R)←(R)-1),指定的字节内容可以在缓存器A,B,C,D,E,H和L之中,动作上都只需要1个机械周期,但以下的写法在8085是没有对应的写法:
(8051) DEC 30H ;减1把内部RAM地址30H的内容
间接字节递减:
DEC @Ri ; 动作:((Ri))←((Ri))-1
此指令动作与808之 “ DCR M
“相同(动作:(M)←(M)-1),8051需要1个机械周期,8085却需要3个机械周期。
7. MUL AB:
把累加器A的内容乘以缓存器B的内容,相乘之后所得的结果,高8位存入B内,低8位存入A内,执行指令需要4个机械周期。8051有乘法的指令,8085没有乘法的指令。
8. DIV AB:
把累加器A的内容除以缓存器B的内容,得到的商存入A内,余数则存入B内,执行指令需要4个机械周期。8085没有除法的指令。
9. DA A:
此指令不可以直接将累加器内16进位制数字转换成BCD码,也不可以使用于BCD码的减法。它是将上一次两个BCD码相加后放在累加器内的和调整成两个四位的BCD码。此指令与8085之
“ DAA “相同,都只需要1个机械周期。
动作:如果 [[(A3-0)>9] 或 [(AC)=1]
则(A3-0)←(A3-0)+6
如果 [[(A7-4)>9] 或 [(C)=1]
则(A7-4)←(A7-4)+6
表6. 8051算术运算指令
|
指 令 |
说 明 |
字节 |
工作周期(时脉数) |
| ADD A,Rn |
缓存器累加至累加器 |
1 |
12 |
| ADD A,direct |
直接字节加至累加器 |
2 |
12 |
| ADD A,@Ri |
间接字节加至累加器 |
1 |
12 |
| ADD A,#data |
常数值加至累加器 |
2 |
12 |
| ADDC A,Rn |
与C一起将缓存器加至累加器 |
1 |
12 |
| ADDC A,direct |
与C一起将直接字节加至累加器 |
2 |
12 |
| ADDC A,@Ri |
与C一起将间接字节加至累加器 |
1 |
12 |
| ADDC A,#data |
与C一起将常数值加至累加器 |
2 |
12 |
| SUBB A,Rn |
累加器减缓存器再减C |
1 |
12 |
| SUBB A,direct |
累加器减直接字节再减C |
2 |
12 |
| SUBB A,@Ri |
累加器减间接字节再减C |
1 |
12 |
| SUBB A,#data |
累加器减常数值再减C |
2 |
12 |
| INC A |
累加器加一 |
1 |
12 |
| INC Rn |
缓存器加一 |
1 |
12 |
| INC direct |
直接字节加一 |
2 |
12 |
| INC @Ri |
间接字节加一 |
1 |
12 |
| DEC A |
累加器减一 |
1 |
12 |
| DEC Rn |
站存器减一 |
1 |
12 |
| DEC direct |
直接字节减一 |
2 |
12 |
| DEC @Ri |
间接字节减一 |
1 |
12 |
| INC DPTR |
数据指针加一 |
1 |
24 |
| MUL AB |
A乘以B |
1 |
48 |
| DIV AB |
A除以B |
1 |
48 |
| DA A |
累加器作BCD调整 |
1 |
12 |
(2). 逻辑运算指令:
共有10种,其中8085不能对应到的指令有:”ANL A,direct”,”ORL A,direct”,”XRL
A,direct”,”CLR A”,”SWAP A”。
1. ANL <dest-byte>,<src-byte>:
累加器与缓存器做AND:
ANL A, Rn ; 动作: (A)←(A) AND (Rn)
此指令动作与8085之 “ ANA R “相同,都只需要1个机械周期。
累加器与立即数据做AND:
ANL A, #data ; 动作: (A)←(A) AND data
此指令动作与8085之 “ ANI I8
“相同,8051需要1个机械周期,8085需要2个机械周期。
累加器与直接字节做AND:
ANL A, direct ; 动作: (A)←(A) AND (direct)
此指令动作与8085之 “ ANA R “相似,都只需要1个机械周期,但以下的写法8085是没有对应的:
ANL A, 30H ;把内部RAM地址30H的内容AND入累加器中
累加器与间接字节做AND:
ANL A, @Ri ; 动作: (A)←(A) AND ((Ri))
此指令动作与8085之 “ ANA M “相同,8051需要1个机械周期,8085需要2个机械周期。
2. ORL <dest-byte>,<src-byte>:
累加器与缓存器做OR:
ORL A, Rn ; 动作: (A)←(A) OR (Rn)
此指令动作与8085之 “ ORA R “相同,都只需要1个机械周期。
累加器与立即数据做OR:
ORL A, #data ; 动作: (A)←(A) OR data
此指令动作与8085之 “ ORI I8
“相同,8051需要1个机械周期,8085需要2个机械周期。
累加器与直接字节做OR:
ORL A, direct ; 动作: (A)←(A) OR (direct)
此指令动作与8085之 “ ORA R “相似,都只需要1个机械周期,但以下的写法8085是没有对应的:
ORL A, 30H ;把内部RAM地址30H的内容OR入累加器中
累加器与间接字节做OR:
ORL A, @Ri ; 动作: (A)←(A) OR ((Ri))
此指令动作与8085之 “ ORA M “相同,8051需要1个机械周期,8085需要2个机械周期。
3. XRL <dest-byte>,<src-byte>:
累加器与缓存器做XOR:
XRL A, Rn ; 动作: (A)←(A) XOR (Rn)
此指令动作与8085之 “ XRA R “相同,都只需要1个机械周期。
累加器与立即数据做XOR:
XRL A, #data ; 动作: (A)←(A) XOR data
此指令动作与8085之 “ XRA I8
“相同,8051需要1个机械周期,8085需要2个机械周期。
累加器与直接字节做XOR:
XRL A, direct ; 动作: (A)←(A) XOR (direct)
此指令动作与8085之 “ XRA R “相似,都只需要1个机械周期,但以下的写法8085是没有对应的:
XRL A, 30H ;把内部RAM地址30H的内容XOR入累加器中
累加器与间接字节做XOR:
XRL A, @Ri ; 动作: (A)←(A) XOR ((Ri))
此指令动作与8085之 “ XRA M “相同,8051需要1个机械周期,8085需要2个机械周期。
4. CLR A:清除累加器
CLR A ; 动作: (A)←0 ; 机械周期:1
8085没有如此动作的指令。
5. CPL A:将累加器的内容反相
CPL A ; 动作: (A)← NOT (A) ; 机械周期:1
此指令动作与8085之 “ CMA “相同,都只需要1个机械周期。
6. RL A:将累加器向左旋转一位
RL A ; 动作: (An+1)←(An) n=0~6
(A0)←(A7)
此指令动作与8085之 “ RLC “相似,都只需要1个机械周期,但8051的指令不改变进位旗标,8085会改变进位旗标:
(8085)
RLC ; 动作:(An+1)←(An) n=0~6
(A0)←(A7) ,(C)←(A7)
7. RLC A:将累加器经进位旗标向左旋转
RLC A ; 动作: (An+1)←(An) n=0~6
(A0)←(C)
(C)←(A7)
此指令动作与8085之 “ RAL “相同,都只需要1个机械周期。
8. RR A:将累加器向左旋转一位
RR A ; 动作: (An)←(An+1) n=0~6
(A7)←(A0)
此指令动作与8085之 “ RRC “相同,都只需要1个机械周期,但
8051的指令不改变进位旗标,8085会改变进位旗标:
(8085)
RLC ; 动作:(An)←(An+1) n=0~6
(A7)←(A0) ,(C)←(A0)
9. RRC A:将累加器经进位旗标向左旋转
RRC A ; 动作: (An)←(An+1) n=0~6
(A7)←(C)
(C)←(A0)
此指令动作与8085之 “ RAR “相同,都只需要1个机械周期。
10. SWAP A:将累加器的高4位和低4位内容互相交换
SWAP A ; 动作: (A3-0)←(A7-4) ; 机械周期:1
此指令动作在8085中没有对应的指令。
表7. 8051逻辑运算指令
|
指 令 |
说 明 |
字节 |
工作周期(时脉数) |
| ANL A,Rn |
缓存器AND至累加器 |
1 |
12 |
| ANL A,direct |
直接字节AND至累加器 |
2 |
12 |
| ANL A,@Ri |
间接字节AND至累加器 |
1 |
12 |
| ANL A,#data |
常数值AND累加器 |
2 |
12 |
| ANL direct,A |
累加器AND至直接字节 |
2 |
12 |
| ANL direct,#data |
常数AND 至直接字节 |
3 |
24 |
| ORL A,Rn |
缓存器OR至累加器 |
1 |
12 |
| ORL A,direct |
直接字节OR至累加器 |
2 |
12 |
| ORL A,@Ri |
间接字节OR至累加器 |
1 |
12 |
| ORL A,#data |
常数值加OR累加器 |
2 |
12 |
| ORL direct,A |
累加器OR至直接字节 |
2 |
12 |
| ORL direct,#data |
常数OR至直接字节 |
3 |
24 |
| XRL A,Rn |
缓存器XRL至累加器 |
1 |
12 |
| XRL A,direct |
直接字节XRL至累加器 |
2 |
12 |
| XRL A,@Ri |
间接字节XRL至累加器 |
1 |
12 |
| XRL A,#data |
常数值加XRL累加器 |
2 |
12 |
| XRL direct,A |
累加器XRL至直接字节 |
2 |
12 |
| XRL direct,#data |
常数XRL 至直接字节 |
3 |
24 |
| CLR A |
清除累加器 |
1 |
12 |
| CPL A |
累加器反相 |
1 |
12 |
| RL A |
累加器向左旋转 |
1 |
12 |
| RLC A |
累加器与C一起向左旋转 |
1 |
12 |
| RR A |
累加器向右旋转 |
1 |
12 |
| RRC A |
累加器与C一起向右旋转 |
1 |
12 |
| SWAP A |
累加器的高低四位交换 |
1 |
12 |
(3). 数据转移指令:
共有8种,其中8085不能对应到的指令有:
” MOV direct,Rn ”,” MOV direct,#data ”,” MOV Rn,direct ”,” MOV
direct,direct “,” MOV DPTR,#data16 “.” MOVC A,@A+<base-reg>”,” XCH <dest-byte>,<src-byte>
“,” MOVX A,@DPTR”,” MOVX @DPTR,A”,”XCHD”。
1. MOV <dest-byte>,<src-byte>:
缓存器内容加载累加器:
MOV A, Rn ; 动作: (A)←(Rn)
此指令动作与8085之 “ MOV A,R “相同,都只需要1个机械周期,但8085”MOV”的指令能提供缓存器与缓存器间数据的转移:
MOV RD, RS ; 动作: (RD)←(RS),RD及RS可为B,C,D,E,H,或L
8085还提供了缓存器对加载累加器的指令:
LDAX RR ; 动作: (A)←(RR),RR为缓存器对B&C或D&E指定的内存地址内容,8085需要2个机械周期。
缓存器内容加载直接字节内:
MOV direct, Rn ; 动作: (direct)←(Rn)
此指令动作与8085之 “ MOV RD,RS
“相似,8051需要2个机械周期,8085只需要1个机械周期,而且都能提供缓存器与缓存器间数据的转移,但8085 ”MOV
RD,RS ”指令,RD不能直接改写成地址。
缓存器内容加载间接字节内:
MOV direct, @Ri ; 动作: (direct)←((Ri))
此指令动作与8085之 “ MOV R,M “相似,都需要2个机械周期,但R不能直接改写为地址。
立即数据加载累加器:
MOV A, #data ; 动作: (A)←#data
此指令动作与8085之 “ MVI A,I8
“相同,8051需要1个机械周期,8085需要2个机械周期。
立即数据加载缓存器:
MOV Rn, #data ; 动作: (Rn)←#data
此指令动作与8085之 “ MVI R,I8
“相同,8051需要1个机械周期,8085需要2个机械周期。
8085还提供了16位立即数据加载缓存器对的指令:
LXI RP,I16 ; 动作: (RP)←I16 ,RP为缓存器对B&C,D&E,H&L,SP,需要3个机械周期。
立即数据加载直接字节内:
MOV direct, #data ; 动作: (direct)←#data
此指令动作与8085之 “ MVI M,I8 “相似,8051需要2个机械周期,8085需要3个机械周期。
立即数据加载间接字节内:
MOV @Ri, #data ; 动作: ((Ri))←#data
此指令动作与8085之 “ MVI M,I8
“相同,8051需要1个机械周期,8085需要3个机械周期。
直接字节内容加载累加器:
MOV A, direct ; 动作:(A)←(direct)
此指令动作与8085之 “ LDA direct “相同,8051需要1个机械周期,8085需要4个机械周期。
直接字节内容加载缓存器:
MOV Rn, direct ; 动作:(Rn)←(direct)
此指令动作与8085之 “ MOV RD,RS “相似,8051需要2个机械周期,8085需要1个机械周期,8085没有将RS置换为地址的写法。
直接字节内容加载直接字节内:
MOV direct, direct ; 动作:(direct)←(direct)
8051需要2个机械周期,8085没有这样的指令。
直接字节内容加载间接字节内:
MOV @Ri, direct ; 动作:((Ri))←(direct)
此指令动作与8085之 “ MOV M,R “相似,都需要2个机械周期。8085是使用缓存器对H&L来完成相同的动作:
LHLD 地址 ; 动作:L ← (地址)
H ← (地址+1) ; 机械周期:5
间接字节内容加载累加器:
MOV A, @Ri ; 动作:(A)←((Ri))
此指令动作与8085之 “ MOV A,M “相同,8051需要1个机械周期,8085需要2 个机械周期。
间接字节内容加载直接字节内:
MOV direct, @Ri ; 动作:(direct)←((Ri))
此指令动作与“相似,都需要2个机械周期。8085是使用8085之 “ MOV R,M
缓存器对H&L来完成相同的动作:
SHLD 地址 ; 动作: (地址) ← L
(地址+1) ← H ; 机械周期:5
累加器内容加载缓存器:
MOV Rn, A ; 动作: (Rn)←(A)
此指令动作与8085之 “ MOV R, A “相同,都只需要1个机械周期。
8085还提供将累加器内容加载缓存器对的指令:
STAX RR ; 动作:(RR)←(A),此指令只能指定缓存器对B&C,D&E,例如:
设B=3FH, C=16H,A=3AH,则
STAX B ; 执行之后,内存地址3F16H含有3AH
累加器内容加载直接字节内:
MOV diret, A ; 动作: (direct)←(A)
此指令动作与8085之 “ STA direct “相同,8051需要2个机械周期,8085需要4个机械周期。
累加器内容加载间接字节内:
MOV @Ri, A ; 动作: ((Ri))←(A)
此指令动作与8085之 “ MOV M,A “相同,8051需要1个机械周期,8085需要2个机械周期。
2. MOV DPTR,#data16:
将16位的常数加载数据指针内。
MOV DPTR, #data16 ; 动作:(DPTR) ← data 15-0, 机械周期:2
MOV #1234H ; 执行后高字节DPH=12H,低字节DPL=34H
8085没有数据指针DPTR,只有储存箱指标SP,且8085没有这样的指令。
3. MOVC A,@A+<base-reg>:
此指令是到程序区里读一个字节数据到累加器,这个字节的地址是由累加器的值加上一个16位基底缓存器所产生的。机械周期皆为2。8085没有这样的指令。
基底缓存器为数据指针:
MOVC A, @A+DPTR ; 动作: (A) ← ((A)+(DPTR))
基底缓存器为程序计数器:
MOVC A, @A+PC ; 动作: (PC) ← (PC) +1
(A) ← ((A)+(PC))
4. MOVX <dest-byte>,<src-byte>:
此指令与8051之” MOV <dest-byte>,<src-byte> ”主要差
别在于”MOVX”是对外部内存做存取动作,而”MOV”是对内部存储器做存取。8085没有内部存储器,所以8085所使用的内存地址都是外部内存。因此,8085对应8051之”MOVX”指令,可以参考前面提过的8051之”MOV”指令部分。
外部RAM的内容载入累加器:
MOVX A,@Ri ; 动作: (A) ← ((Ri)) ;机械周期:2
DPTR寻址的外部RAM内容载入累加器:
MOVX A,@DPTR ; 动作: (A) ← ((DPTR)) ;机械周期:2
把累加器的内容加载外部RAM的Ri地址内:
MOVX @Ri,A ; 动作: ((Ri)) ← (A) ;机械周期:2
把累加器的内容加载外部RAM的DPTR地址内:
MOVX @DPTR,A ; 动作: (DPTR) ← (A) ;机械周期:2
5. PUSH direct: 将直接字节的内容推入堆栈器内。
PUSH direct ; 动作: (SP) ← (SP)+1
((SP)) ← (direct) ; 机械周期:2
此指令与8085之 " PUSH RR "有相似的作用,RR是缓存器对B&C,D&E,H&L和PSW(A&F),机械周期:3,但动作SP是呈现递减的情形:
(SP) ← (SP)-2, STACK←RR
例如:
(8051)
设SP=09,DPTR=0123H
PUSH DPL ;将23H存入RAM的0AH地址
PUSH DPH ;将01H存入RAM的0BH地址
(8085)
设B=2AH,C=4CH,SP=9AAFH
PUSH B ; 将2A存入RAM的9AAEH地址,4CH存入RAM的9AADH地址
所以可以看出8085可以利用缓存器做到数据指针的角色。
6. POP direct:从堆栈区取回数据。
POP direct ; 动作: (direct) ← ((SP))
(SP) ← (SP)-1 ; 机械周期:2
此指令与8085之 " POP RR "有相似的作用,RR是缓存器对B&C,D&E,H&L和PSW(A&F),机械周期:3,但动作SP是呈现递加的情形:
RR←STACK, (SP)←(SP)+2
7. XCH <dest-byte>,<src-byte>:
累加器的内容和缓存器的内容互换:
XCH A,Rn ; 动作: (A) ←→ (Rn) ;机械周期:1
8085没有此指令动作,但8085提供缓存器H&L与D&E内容的互相交换的指令:
XCHG ; 动作: (HL) ←→ (DE) ;机械周期:1
例如:
(8085) 设HL=1234H,DE=ABCDH
XCHG ;执行后,HL=ABCDH,DE=1234H
累加器的内容和直接字节的内容互换:
XCH A,direct ; 动作: (A) ←→ (direct) ;机械周期:1
8085没有此指令动作。
累加器的内容和间接字节的内容互换:
XCH A,@Ri ; 动作: (A) ←→ ((Ri)) ;机械周期:1
8085没有此指令动作。但8085提供储存箱顶两组位内容和缓存器对H&L的内容互换指令:
XTHL ; 动作: (STACK) ←→ (HL) ;机械周期:5
例如:
(8085)
设SP=10ADH,HL=0B3CH,内存地址10ADH含有F0H,内存地址10AEH含有0DH,那么执行
XTHL ;执行后,L=F0H,H=0DH,内存地址10ADH含有3CH,内存地址10AEH含有0BH。
8. XCHD A,@Ri :交换低四位
XCHD A,@Ri ; 动作: (A3-0) ←→ ((Ri))3-0
;机械周期:1
8085没有这样的指令。
表8. 8051数据转移指令
|
指 令 |
说 明 |
字节 |
工作周期(时脉数) |
| MOV A,Rn |
缓存器内容移至累加器 |
1 |
12 |
| MOV A,direct |
直接字节内容移至累加器 |
2 |
12 |
| MOV A,@Ri |
间接字节内容移至累加器 |
1 |
12 |
| MOV A,#data |
常数值移至累加器 |
2 |
12 |
| MOV Rn,A |
累加器内容移至缓存器 |
1 |
12 |
| MOV Rn,direct |
直接字节内容移至缓存器 |
2 |
24 |
| MOV Rn,#data |
常数值移至缓存器 |
2 |
12 |
| MOV direct,A |
累加器内容移至直接字节 |
2 |
12 |
| MOV direct,Rn |
缓存器内容移至直接字节 |
2 |
24 |
| MOV direct,direct |
直接字节内容移至直接位
元组 |
3 |
24 |
| MOV direct,@Ri |
间接字节内容移至直接位
元组 |
2 |
24 |
| MOV direct,#data |
常数移至直接字节 |
3 |
24 |
| MOV @Ri,A |
累加器内容移至间接字节 |
1 |
12 |
| MOV @Ri,direct |
直接字节内容移至间接位
元组 |
2 |
24 |
| MOV @Ri,#data |
常数移至间接字节 |
2 |
12 |
| MOV DPTR,#data 16 |
16位常数移至数据指针 |
3 |
24 |
| MOVC A,@A+DPTR |
程序内存的数据移入累加器 |
1 |
24 |
| MOVC A,@A+PC |
程序内存的数据移入累加器 |
1 |
24 |
| MOVX A,@Ri |
外部RAM的数据移入累加器
(8位寻址) |
1 |
24 |
| MOVX A,@DPTR |
外部RAM的数据移入累加器
(16位寻址) |
|
|
| MOVX @Ri,A |
累加器内容写到外部RAM
(8位地址) |
1 |
24 |
| MOVX @DPTR,A |
累加器内容写到外部RAM
(16位地址) |
1 |
24 |
| PUSH direct |
直接字节内容放至堆栈区 |
2 |
24 |
| POP direct |
从堆栈区拿回数据至直接位
元组 |
2 |
24 |
| XCH A,Rn |
累加器与缓存器的内容互换 |
1 |
12 |
| XCH A,direct |
累加器与直接字节的内容
互相交换 |
2 |
12 |
| XCH A,@Ri |
累加器与间接字节的内容
互相交换 |
1 |
12 |
| XCHD A,@Ri |
累加器与间接字节的低四
位互相交换 |
1 |
12 |
(4). 布尔变量操作指令:
共有11种,其中8085不能对应的指令有:”CLR bit”,”SETB bit”,”ANL C,<src-byte>”,”ORL
C,<src-byte>”,”MOV <dest-bit>,<src-bit>”,”JB bit,rel”,”JNB
bit,rel”,”JBC bit,rel”.
1. CLR bit:
清除进位旗标内容:
CLR C ; 动作: (C) ← 0 ;机械周期:1
8085采用以下三种方式清除进位旗标:
(1) STC ;设置进位旗标为1
CMC ;补算(反相)进位旗标
(2) ANA A ;A的内容不变,但进位旗标被清除为0
(3) ORA A ;A的内容不变,但进位旗标被清除为0
清除直接位内容:
CLR bit ; 动作: (bit) ← 0 ;机械周期:1
8085没有此指令动作。
2. SETB bit:
设定进位旗标内容:
SETB C ; 动作: (C) ← 1
此指令动作与8085之 “ STC “相同,都只需要1个机械周期。
设定直接位内容:
SETB bit ; 动作: (bit) ← 1 ;机械周期:1
8085没有此指令动作。
3. CPL bit:
将进位旗标反相:
CPL C ; 动作: (C) ← NOT (C)
此指令动作与8085之 “ CMC “相同,都只需要1个机械周期。
将直接位反相:
CPL bit ; 动作: (bit) ← NOT (bit) ; 机械周期:1
8085没有此指令动作。
4. ANL C,<src-byte>:
将进位旗标与直接位内容做AND:
ANL C,bit ; 动作: (C) ← (C) AND (bit)
将进位旗标与直接位内容反相做AND:
ANL C,/bit ; 动作: (C) ← (C) AND (NOT(bit))
以上指令都需要2个机械周期,但8085没有这样的指令。
5. ORL C,<src-byte>:
将进位旗标与直接位内容做ORL:
ORL C,bit ; 动作: (C) ← (C) ORL (bit)
将进位旗标与直接位内容反相做AND:
ORL C,/bit ; 动作: (C) ← (C) ORL (NOT(bit))
以上指令都需要2个机械周期,但8085没有这样的指令。
6. MOV <dest-bit>,<src-bit>:
将直接位的内容加载进位旗标内:
MOV C,bit ; 动作: (C) ← (bit) ;机械周期:1
将进位旗标的内容加载直接位内:
MOV bit,C ; 动作:(bit) ← (C) ;机械周期:2
8085没有以上的指令动作。
7. JC rel: 如果C=1就跳至相对地址
JC rel ; 动作: 如果C=0, (PC) ← (PC)+2
如果 C=1, (PC) ← (PC)+相对地址
此指令与8085之 “ JC address “相同,8051需要2个机械周期,8085需要2或3个周期。其动作:
JC address ; 如果 C=1, (PC) ← 地址
如果C=0, (PC) ← (PC)+1,执行下一指令
8. JNC rel: 如果C=0就跳至相对地址
JNC rel ; 动作: 如果C=0, (PC) ← (PC)+相对地址 如果 C=1, (PC) ← (PC)+2
此指令与8085之 “ JNC address “相同,8051需要2个机械周期,8085需要2或3个周期。其动作:
JNC address ; 如果 C=0, (PC) ← 地址
如果C=1, (PC) ← (PC)+1,执行下一指令
9. JB bit,rel: 如果bit=1就跳至相对地址
JB bit,rel ; 动作: 如果bit=1, (PC) ← (PC)+相对地址
如果bit=0, (PC) ← (PC)+3
其机械周期为2,8085没有此指令动作。
10. JNB bit,rel: 如果bit=0就跳至相对地址
JNB bit,rel ; 动作: 如果bit=0, (PC) ← (PC)+相对地址
如果bit=1, (PC) ← (PC)+3
其机械周期为2,8085没有此指令动作。
11. JBC bit,rel: 如果bit=1就跳至相对地址,并且清除bit
JBC bit,rel ; 动作: 如果bit=1, (PC) ← (PC)+相对地址
(bit) ← 0
如果bit=0, (PC) ← (PC)+3
其机械周期为2,8085没有此指令动作。
表9. 布尔变量指令
|
指 令 |
说 明 |
字节 |
工作周期(时脉数) |
| CLR C |
清除进位旗标 |
1 |
12 |
| CLR bit |
清除bit |
2 |
12 |
| SETB C |
设定进位旗标 |
1 |
12 |
| SETB bit |
设定bit=1 |
2 |
12 |
| CPL C |
进位旗标反相 |
1 |
12 |
| CPL bit |
bit反相 |
2 |
12 |
| ANL C,bit |
bit AND 至进位旗标 |
2 |
24 |
| ANL C,/bit |
bit 反相后再AND至进位旗标 |
2 |
24 |
| ORL C,bit |
bit OR 至进位旗标 |
2 |
24 |
| ORL C,/bit |
bit 反相后OR至进位旗标 |
2 |
24 |
| MOV C,bit |
bit之状态移至进位旗标 |
2 |
12 |
| MOV bit,C |
进位旗标之状态移至bit |
2 |
24 |
| JC rel |
若C=1就跳跃 |
2 |
24 |
| JNC rel |
若C=0就跳跃 |
2 |
24 |
| JB bit,rel |
若bit=1就跳跃 |
3 |
24 |
| JNB bit,rel |
若bit=0就跳跃 |
3 |
24 |
| JBC bit,rel |
若bit=1就跳跃,且清除此位 |
3 |
24 |
(5). 程序分控(Branch)指令:
共13种,其中8085不能对应的指令有:” ACALL addr11 ”,” RETI “,” AJMP addr11 “,”
SJMP “,” JMP @A+DPTR “,“ JZ rel “,” JNZ rel “,CJNE <dest-byte>,<src-byte>
“,” DJNZ <byte>,rel “.
1. ACALL addr11:绝对子程序呼叫
ACALL addr11 ; 动作:(PC) ← (PC)+2
(SP) ← (SP)+1
((SP)) ← (PC7-0)
(SP) ← (SP)+1
((SP)) ← (PC15-8)
(PC10-0) ← page address ;机械周期:2
由于有效地址只有11位,所以欲呼叫之子程序,地址必须在相同的2K byte范围内。8085没有此动作指令。
2. LCALL addr16: 远程子程序呼叫
LCALL addr16 ; 动作:(PC) ← (PC)+2
(SP) ← (SP)+1
((SP)) ← (PC7-0)
(SP) ← (SP)+1
((SP)) ← (PC15-8)
(PC15-0) ← page address ;机械周期:2
由于有效地址为16位,所以呼叫的子程序地址可在64K byte程序内存的任何地址,本指令可简写为” CALL
address ”。此指令与8085之 “ CALL address “有相同的效用,8085推入堆栈区的动作是呈递减:
CALL address ;动作: (SP) ← (SP)-1 ,STACK←PC8-15
(SP) ← (SP)-1 ,STACK←PC0-7
(PC15-0) ← address ;机械周期:5
3. RET : 由子程序返回主程序
RET ; 动作: (PC15-8) ← ((SP))
(SP) ← (SP)-1
(PC7-0) ← ((SP))
(SP) ← (SP)-1
此指令动作与8085之 “ RET “相同,一般来说RET和CALL连用,8051需要2个机械周期,8085需要3个机械周期。
4. RETI: 由中断子程序返回主程序
RET ; 动作: (PC15-8) ← ((SP))
(SP) ← (SP)-1
(PC7-0) ← ((SP))
(SP) ← (SP)-1 ; 机械周期:2
在8051中断子程序一定要用RETI做结尾,8085没有这样的指令。
5. AJMP addr11:绝对跳跃
AJMP addr11 ; 动作: (PC) ← (PC)+2
(PC10-0) ← page address ;机械周期:2
由于有效地址只有11位,所以欲跳跃之目的地址,必须在相同的2K bytes范围内。8085没有此动作指令。
6. LJMP addr16:远程跳跃
LJMP addr16 ; 动作:(PC) ← address15-0
由于有效地址为16位,所以跳跃之目的地址可在64K byte程序内存的任何地址,本指令可简写为” JMP address
”。此指令与8085之 “ JMP address “相同,8051需要2个机械周期,8085需要3个机械周期。
7. SJMP rel:短程跳跃
SJMP ; 动作: (PC) ← (PC)+2
(PC) ← (PC)+相对地址 ; 机械周期:2
8085没有这样的指令。
8. JMP @A+DPTR:间接跳跃
JMP @A+DPTR ; 动作: (PC) ← (A)+(PC)+2 ; 机械周期:2
8085没有这样的指令。
9. JZ rel: 如果累加器不等于零,则跳至相对地址
JZ rel ; 动作: 如果A≠0, (PC) ← (PC)+相对地址
如果A=0,(PC) ← (PC)+2 ;机械周期:2
8085没有这样的指令。而8085的 “ JZ address
“指令动作决定于零旗标值,如果零旗标值等于1,则跳至指定的地址;如果零旗标值等于0,则程序执行下一顺序指令。机械周期2或3。
(8085) JZ address ;若Z=1, (PC) ← (PC)+地址
若Z=0, (PC) ← (PC)+1 ;
10. JNZ rel: 如果累加器等于零,则跳至相对地址
JNZ rel ; 动作: 如果A=0, (PC) ← (PC)+相对地址
如果A≠0,(PC) ← (PC)+2 ;机械周期:2
8085没有这样的指令。而8085的 “ JNZ address
“指令动作决定于零旗标值,如果零旗标值等于0,则跳至指定的地址;如果零旗标值等于1,则程序执行下一顺序指令。机械周期:2或3。
(8085) JNZ address ;若Z=0, (PC) ← (PC)+地址
若Z=1, (PC) ← (PC)+1
11. CJNE <dest-byte>,<src-byte>,rel:
累加器的内容不等于直接字节的内容就跳至相对地址:
CJNE A,direct,rel ;
动作: 若(A)=(direct), (PC) ← (PC)+3
若(A)≠(direct), (PC) ← (PC)+相对地址
若(A) < (direct),则(C) ← 1
否则(C) ← 0
累加器的内容不等于立即数据就跳至相对地址:
CJNE A,#data,rel ;
动作: 若(A)=data, (PC) ← (PC)+3
若(A)≠data, (PC) ← (PC)+相对地址
若(A) < (data),则(C) ← 1
否则(C) ← 0
缓存器的内容不等于立即数据就跳至相对地址:
CJNE Rn,#data,rel ;
动作: 若(Rn)=data, (PC) ← (PC)+3
若(Rn)≠data, (PC) ← (PC)+相对地址
若(Rn) < data,则(C) ← 1
否则(C) ← 0
间接字节的内容不等于立即数据就跳至相对地址:
CJNE @Ri,#data,rel ;
动作: 若((Ri))=data, (PC) ← (PC)+3
若((Ri))≠data, (PC) ← (PC)+相对地址
若((Ri)) < data,则(C) ← 1
否则(C) ← 0
以上指令都需要2个机械周期,但8085没有这样的指令。
12. DJNZ <byte>,rel:
缓存器的内容递减,结果不等于零则跳至相对地址:
DJNZ Rn,rel ;
动作: (Rn) ← (Rn)-1
若Rn≠0, 则(PC) ← (PC)+相对地址
若Rn=0, 则(PC) ← (PC)+2
直接字节的内容递减,结果不等于零则跳至相对地址:
DJNZ direct,rel ;
动作: direct ← direct-1
若direct≠0,则(PC) ← (PC)+相对地址
若direct=0,则(PC) ← (PC)+3
以上指令都需要2个机械周期,但8085没有这样的指令。
13. NOP :无动作。
动作:(PC) ← (PC)+1
此指令动作与8085之 “ NOP “相同,都需要1个机械周期。
表10. 程序分控指令
|
指 令 |
说 明 |
字节 |
工作周期(时脉数) |
| ACALL addr11 |
绝对式子程序呼叫 |
2 |
24 |
| LCALL addr16 |
远程子程序呼叫 |
3 |
24 |
| RET |
从子程序返回 |
1 |
24 |
| RETI |
从中断子程序返回 |
1 |
24 |
| AJMP addr11 |
绝对式跳跃 |
2 |
24 |
| LJMP addr11 |
远程跳跃 |
3 |
24 |
| SJMP rel |
短程跳跃 |
2 |
24 |
| JMP @A+DPTR |
间接跳跃 |
1 |
24 |
| JZ rel |
若A=0就跳跃 |
2 |
24 |
| JNZ rel |
若A≠0就跳跃 |
2 |
24 |
| CJNE A,direct,rel |
若累加器与直接字节内容不
相等就跳跃 |
3 |
24 |
| CJNE A,#data,rel |
若累加器内容不等于data就
跳跃 |
3 |
24 |
| CJNE Rn,#data,rel |
若缓存器内容不等于data就
跳跃 |
3 |
24 |
| CJNE @Ri,#data,rel |
若间接字节内容不等于data
就跳跃 |
3 |
24 |
| DJNZ Rn,rel |
缓存器内容减一,若不等于零
就跳跃 |
2 |
24 |
| DJNZ direct,rel |
直接地址内容减一,若不等于零
就跳跃 |
3 |
24 |
| NOP |
没动作 |
1 |
12 |
(ii). 8085的指令集
(1). 算术运算指令:8051的算术运算指令都能对应到8085。
- ADD 加到累加器
- ADI 以立即数据加到累加器
- ADC 利用进位旗标加到累加器
- ACI 利用进位旗标以立即数据加到累加器
- SUB 从累加器减去
- SUI 累加器减去立即数据
- SBB 利用贷位旗标从累加器中减去
- SBI 利用贷位旗标从累加器中减去立即数据
- INR 增加指定组元1
- DCR 减少指定组元1
- INX 增加缓存器对1
- DCX 减少缓存器对1
- DAD 将指定的缓存器对的内容加到H和L缓存器对中
- DAA 调整累加器的8位数值成两个4位二进制代码十
进位数字,在多字节算术运算中,DAA是紧跟在算术运算指令之后。
(表中目的码:
ppqq代表4个16进位数字内存的地址,
YY代表两个16进位数字数据YYYY代表4个16进位数字数据,
X代表数据表选择的二进制数,
ddd代表识别目的缓存器的二进制数,
sss代表识别来源缓存器的二进制数:
000=B,001=C,010=D,011=E,100=H,101=L,111=A。
机械周期种类为:1=4个T状态的操作元取出,
2=6个T状态的操作元取出,
3=内存读取,4=I/O读取,5=内存写入,6=I/O写入,7=通径等候)
表11. 8085算术运算指令目的码和执行周期
|
指令 |
目的码 |
组元 |
时脉周期 |
8085A
机械周期种类 |
|
8080A |
8085A |
| ACI DATA |
CE YY |
2 |
7 |
7 |
1 3 |
| ADC REG |
10001XXX |
1 |
4 |
4 |
1 |
| ADC M |
8E |
1 |
7 |
7 |
1 3 |
| ADD REG |
10000XXX |
1 |
4 |
4 |
1 |
| ADD M |
86 |
1 |
7 |
7 |
1 3 |
| ADI DATA |
C6 YY |
2 |
7 |
7 |
1 3 |
| DAA |
27 |
1 |
4 |
4 |
1 |
| DAD RP |
00XX1001 |
1 |
10 |
10 |
1 7 7 |
| DCR REG |
00XXX101 |
1 |
5 |
4 |
1 |
| DCR M |
35 |
1 |
10 |
10 |
1 3 5 |
| DCX RP |
00XX1011 |
1 |
5 |
6 |
2 |
| INR REG |
00XXX100 |
1 |
5 |
4 |
1 |
| INR M |
34 |
1 |
10 |
10 |
1 3 5 |
| INX RP |
00XX0011 |
1 |
5 |
6 |
2 |
| SBB REG |
10011XXX |
1 |
4 |
4 |
1 |
| SBB M |
9E |
1 |
7 |
7 |
1 3 |
| SBI DATA |
DE YY |
2 |
7 |
7 |
1 3 |
| SUB REG |
10010XXX |
1 |
4 |
4 |
1 |
| SUB M |
96 |
1 |
7 |
7 |
1 3 |
| SUI DATA |
D6 YY |
2 |
7 |
7 |
|
(2). 逻辑运算指令:其中8051不能对应的指令有:”CMP R”,”CMP M”,”CPI I8 “。
- ANA 与累加器AND运算
- ANI 利用立即数据与累加器AND运算
- ORA 与累加器OR运算
- ORI 利用立即数据与累加器OR运算
- XRA 与累加器XOR运算
- XRI 利用立即数据与累加器XOR运算
- CMP 与累加器比较:比较的结果由进位旗标和零旗标表示。
CMP R ; 动作: 两值相等时, Z=1
两值同号时,累加器值较大→Z=0,C=0
两值同号时,累加器值较小→Z=0,C=1
两值异号或其中一值为补码时,累加器值较大→Z=0,C=0
两值异号或其中一值为补码时,累加器值较小→Z=0,C=1
机械周期:1
CMP M ;动作如" CMP R ",但机械周期为2。
- CPI 利用立即数据与累加器比较,结果由进位旗标和零旗标表示。
CPI I8 ; 动作: 两值相等时, Z=1
两值同号时,累加器值较大→Z=0,C=0
两值同号时,累加器值较小→1Z=0,C=1
两值异号或其中一值为补码时,累加器值较大→Z=0,C=0
两值异号或其中一值为补码时,累加器值较小→Z=0,C=1
机械周期:2
- RLC 左旋转累加器一位
- RRC 右旋转累加器一位
- RAL 左旋转累加器一位,经过进位数元
- RAR 右旋转累加器一位,经过进位数元
- CMA 补算累加器
- CMC 补算进位旗标
- STC 设置进位旗标
表12. 8085逻辑运算指令目的码和执行周期
|
指令 |
目的码 |
组元 |
时脉周期 |
8085A
机械周期种类 |
|
8080A |
8085A |
| ANA REG |
10100XXX |
1 |
4 |
4 |
1 |
| ANA M |
A6 |
1 |
7 |
7 |
1 3 |
| ANI DATA |
E6 YY |
2 |
7 |
7 |
1 3 |
| CMA |
2F |
1 |
4 |
4 |
1 |
| CMC |
3F |
1 |
4 |
4 |
1 |
| CMP REG |
10111XXX |
1 |
4 |
4 |
1 |
| CMP M |
BE |
1 |
7 |
7 |
1 3 |
| CPI DATA |
FE YY |
2 |
7 |
7 |
1 3 |
| ORA REG |
10110XXX |
1 |
5 |
4 |
1 |
| ORA M |
B6 |
1 |
7 |
7 |
1 3 |
| ORI DATA |
F6 YY |
2 |
7 |
7 |
1 3 |
| RAL |
17 |
1 |
4 |
4 |
1 |
| RAR |
1F |
1 |
4 |
4 |
1 |
| RLC |
07 |
1 |
4 |
4 |
1 |
| RRC |
0F |
1 |
4 |
4 |
1 |
| STC |
37 |
1 |
4 |
4 |
1 |
| XRA REG |
10101XXX |
1 |
4 |
4 |
1 |
| XRA M |
AE |
1 |
7 |
7 |
1 3 |
| XRI DATA |
EE YY |
2 |
7 |
7 |
3 |
(3)数据转移指令:其中8051不能对应的指令有:” XCHG “,” XTHL “。
- MOV 转移
- MVI 转移立即数据
- LDA 直接由内存装载累加器
- STA 直接储存累加器到内存
- LHLD 直接由内存装载H和L缓存器
- SHLD 直接储存H和L缓存器到内存
- LXI 以立即数据装载缓存器对
- LDAX 由缓存器对里的地址指定的内存装载累加器
- STAX 储存累加器到缓存器对里的地址指定的内存中
- XCHG 将缓存器对D和E与缓存器对H和L交换
XCHG ; 动作: (HL) ←→ (DE) ;机械周期:1
- XTHL 以缓存器对H和L与储存箱顶两组元交换
XTHL ; 动作: (STACK) ←→ (HL) ;机械周期:5
表13. 8085数据转移指令目的码和执行周期
|
指令 |
目的码 |
组元 |
时脉周期 |
8085A
机械周期种类 |
|
8080A |
8085A |
| LDA ADDR |
3A ppqq |
3 |
13 |
13 |
1 3 3 3 |
| LDAX RP |
000X0001 |
3 |
10 |
10 |
1 3 |
| LHLD ADDR |
2A ppqq |
3 |
16 |
16 |
1 3 3 3 3 |
| LXI RP,DATA16 |
00XX0001
YYYY |
3 |
10 |
10 |
1 3 3 |
| MOV REG,REG |
01dddsss |
1 |
5 |
4 |
1 |
| MOV M,REG |
01110sss |
3 |
10 |
10 |
1 5 |
| MOV REG,M |
01ddd110 |
1 |
7 |
7 |
1 3 |
| MVI REG,DATA |
00ddd110
YYYY |
2 |
7 |
7 |
1 3 |
| MVI M,DATA |
36 YY |
2 |
10 |
10 |
1 3 5 |
| SHLD ADDR |
22 ppqq |
3 |
16 |
16 |
1 3 3 5 5 |
| STA ADDR |
32 ppqq |
3 |
13 |
13 |
1 3 3 5 |
| STAX RP |
000X0010 |
1 |
7 |
7 |
1 5 |
| XCHG |
EB |
1 |
4 |
4 |
1 |
| XTHL |
E3 |
1 |
18 |
16 |
5 |
(4)分控指令:
1. 无条件分控指令 :
在任何情况下都改变程序执行的正常顺序,8051都有指令可以对应。
1.1 JMP 跳控
1.2 CALL 叫控
1.3 RET 回转
2. 条件分控指令:
取决于决策条件是否成立。8085于取出指令第二字节时试验条件,若特定的状况没有满足,就会跳越过指令的第二字节去取出下一指令的操作码。
“,
2.1 条件跳控:
8051不能对应的指令有:” JZ “,” JNZ “,” JPE “,” JPO “,JP “,” JM “,” JPE
“,” JPO “.
2.1.1 JC address: 若进位旗标等于1,跳控到指定的地址。
2.1.2 JNC address: 若进位旗标等于0,跳控到指定的地址。
2.1.3 JZ address: 若零旗标等于1,跳控到指定的地址。
8051没有这样的指令。机械周期:2或3。
2.1.4 JNZ address: 若零旗标等于0,跳控到指定的地址。
8051没有这样的指令。机械周期:2或3。
2.1.5 JP address: 若带号旗标等于0,跳控到指定的地址。
动作: 若S=0,(PC) ← 地址
若S=1,(PC) ← (PC)+1 ,执行下一指令。
8051没有这样的指令。机械周期: 2或3。
2.1.6 JM address: 若带号旗标等于1,跳控到指定的地址。
动作: 若S=1,(PC) ← 地址
若S=0,(PC) ← (PC)+1 ,执行下一指令。
8051没有这样的指令。机械周期: 2或3。
2.1.7 JPE address: 若同位数旗标等于1,跳控到指定的地址。
动作: 若P=1,(PC) ← 地址
若P=0,(PC) ← (PC)+1 ,执行下一指令。
8051没有这样的指令。机械周期: 2或3。
2.1.8 JPO address: 若同位数旗标等于0,跳控到指定的地址。
动作: 若P=1,(PC) ← 地址
若P=0,(PC) ← (PC)+1 ,执行下一指令。
8051械周期: 2或3。没有这样的指令。机
2.2 条件叫控:
8051不能对应以下的指令,不过8051可以使用相同的指令组合对应8085”CC”与”CNC”。
2.2.1 CC address: 具有JC和PUSH指令的组合功能。
动作: 若C=1,(SP) ← (SP)-1,(STACK)←(PC8-15)
(SP) ← (SP)-1,(STACK)←(PC0-7 )
(PC) ← 地址
若C=0,(PC) ← (PC)+1
机械周期: 2或5。
2.2.2 CNC address: 具有JNC和PUSH指令的组合功能。
动作: 若C=0,(SP) ← (SP)-1,(STACK)←(PC8-15)
(SP) ← (SP)-1,(STACK)←(PC0-7 )
(PC) ← 地址
若C=1,(PC) ← (PC)+1
机械周期: 2或5。
2.2.3 CZ address: 具有JZ和PUSH指令的组合功能。
动作: 若Z=1,(SP) ← (SP)-1,(STACK)←(PC8-15)
(SP) ← (SP)-1,(STACK)←(PC0-7)
(PC) ← 地址
若Z=0,(PC) ← (PC)+1
机械周期: 2或5。
2.2.4 CNZ address: 具有JNZ和PUSH指令的组合功能。
动作: 若Z=0,(SP) ← (SP)-1,(STACK)←(PC8-15)
(SP) ← (SP)-1,(STACK)←(PC0-7)
(PC) ← 地址
若Z=1,(PC) ← (PC)+1
机械周期: 2或5。
2.4.5 CP address: 具有JP和PUSH指令的组合功能。
动作: 若S=0,(SP) ← (SP)-1,(STACK)←(PC8-15)
(SP) ← (SP)-1,(STACK)←(PC0-7)
(PC) ← 地址
若S=1,(PC) ← (PC)+1
机械周期: 2或5。
2.4.6 CM address: 具有JM和PUSH指令的组合功能。
动作: 若S=1,(SP) ← (SP)-1,(STACK)←(PC8-15)
(SP) ← (SP)-1,(STACK)←(PC0-7)
(PC) ← 地址
若S=0,(PC) ← (PC)+1
机械周期: 2或5。
2.4.7 CPE address: 具有JPE和PUSH指令的组合功能。
动作: 若P=1,(SP) ← (SP)-1,(STACK)←(PC8-15)
(SP) ← (SP)-1,(STACK)←(PC0-7)
(PC) ← 地址
若P=0,(PC) ← (PC)+1
机械周期: 2或5。
2.4.8 CPO address: 具有JPO和PUSH指令的组合功能。
动作: 若P=0,(SP) ← (SP)-1,(STACK)←(PC8-15 )
(SP) ← (SP)-1,(STACK)←(PC0-7 )
(PC) ← 地址
若P=1,(PC) ← (PC)+1
机械周期: 2或5。
2.3 条件回转:
2.3.1 RC :若进位旗标等于1,由储存箱中取出两字节数据,存入程序计数器中。
动作:若C=1,(PC)←(STACK), (SP)←(SP)+2
若C=0,(PC)←(PC)+1
机械周期:1或3。
2.3.2 RNC:若进位旗标等于0,由储存箱中取出两字节数据,存入程序计数器中。
动作:若C=0,(PC)←(STACK), (SP)←(SP)+2
若C=1,(PC)←(PC)+1
机械周期:1或3。
2.3.3 RZ: 若零旗标等于1,由储存箱中取出两字节数据,存入程序计数器中。
动作:若Z=1,(PC)←(STACK), (SP)←(SP)+2
若Z=0,(PC)←(PC)+1
机械周期:1或3。
2.3.4 RNZ:若零旗标等于0,由储存箱中取出两字节数据,存入程序计数器中。
动作:若Z=0,(PC)←(STACK), (SP)←(SP)+2
若Z=1,(PC)←(PC)+1
机械周期:1或3。
2.4.5 RP: 若带号旗标等于1,由储存箱中取出两字节数据,存入程序计数器中。
动作:若S=1,(PC)←(STACK), (SP)←(SP)+2
若S=0,(PC)←(PC)+1
机械周期:1或3。
2.4.6 RM: 若带号旗标等于0,由储存箱中取出两字节数据,存入程序计数器中。
动作:若S=0,(PC)←(STACK), (SP)←(SP)+2
若S=1,(PC)←(PC)+1
机械周期:1或3。
2.4.7 RPE:若同位旗标等于1,由储存箱中取出两字节数据,存入程序计数器中。
动作:若P=1,(PC)←(STACK), (SP)←(SP)+2
若P=0,(PC)←(PC)+1
机械周期:1或3。
2.4.8 RPO:若同位旗标等于1,由储存箱中取出两字节数据,存入程序计数器中。
动作:若P=0,(PC)←(STACK), (SP)←(SP)+2
若P=1,(PC)←(PC)+1
机械周期:1或3
表14。 条件回转指令
|
条件跳控 |
条件叫控 |
条件回转 |
试验条件 |
|
JC |
CC |
RC |
进位(C=1) |
|
JNC |
CNC |
RNC |
无进位(C=0) |
|
JZ |
CZ |
RZ |
零(Z=1) |
|
JNZ |
CNZ |
RNZ |
非零(Z=0) |
|
JP |
CP |
RP |
正数(S=0) |
|
JM |
CM |
RM |
负数(S=1) |
|
JPE |
CPE |
RPE |
偶同位数(P=1) |
|
JPO |
CPO |
RPO |
奇同位数(P=0) |
3. 其它两个指令:8051没有这样的指令。
3.1 PCHL 转移H和L给程序计数器
动作: (PC8-15) ← (H),(PC0-7) ← (L)
机械周期:1
3.2 RST 用于中断的特殊重新开始指令
动作: (RST5,4,3) ← 地址码
机械周期:3
表15. 8085分控指令目的码和执行周期
|
指令 |
目的码 |
组元 |
时脉周期 |
8085A
机械周期种类 |
|
8080A |
8085A |
| CALL LABLE |
CD ppqq |
3 |
17 |
18 |
2 3 3 5 5 |
| CC LABLE |
DC ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| CM LABLE |
FC ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| CNC LABLE |
D4 ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| CNZ LABLE |
C4 ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| CP LABLE |
F4 ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| CPE LABLE |
EC ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| CPO LABLE |
E4 ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| CZ LABLE |
CC ppqq |
3 |
11/17 |
9/18 |
2 3,2 3 3 5 5 |
| JC LABLE |
DA ppqq |
3 |
10 |
7/10 |
1 3,1 3 3 |
| JM LABLE |
FA ppqq |
3 |
10 |
7/10 |
1 3,1 3 3 |
| JMP LABLE |
C3 ppqq |
3 |
10 |
10 |
1 3 3 |
| JNC LABLE |
D2 ppqq |
3 |
10 |
7/10 |
1 3,1 3 3 |
| JNZ LABLE |
C2 ppqq |
3 |
10 |
7/10 |
1 3,1 3 3 |
| JP LABLE |
F2 ppqq |
3 |
10 |
7/10 |
1 3,1 3 3 |
| JPE LABLE |
EA ppqq |
3 |
10 |
7/10 |
1 3,1 3 3 |
| JPO LABLE |
E2 ppqq |
3 |
10 |
7/10 |
1 3,1 3 3 |
| JZ LABLE |
CA ppqq |
3 |
10 |
7/10 |
1 3 3 3 |
| PCHL |
E9 |
1 |
5 |
6 |
2 |
| RC |
D8 |
1 |
5/11 |
6/12 |
2,2 3 3 |
| RET |
C9 |
1 |
10 |
10 |
1 3 3 |
| RM |
F8 |
1 |
5/11 |
6/12 |
2,2 3 3 |
| RNC |
D0 |
1 |
5/11 |
6/12 |
2,2 3 3 |
| RNZ |
C0 |
1 |
5/11 |
6/12 |
2,2 3 3 |
| RP |
F0 |
1 |
5/11 |
6/12 |
2,2 3 3 |
| RPE |
E8 |
1 |
5/11 |
6/12 |
2,2 3 3 |
| RPO |
E0 |
1 |
5/11 |
6/12 |
2,2 3 3 |
| RST N |
11XXX111 |
1 |
11 |
12 |
2 3 3 |
| RZ |
C8 |
1 |
5/11 |
6/12 |
2,2 3 3 |
(5). 储存箱,输入/输出和机械控制指令:
其中8051没有的指令:” XTHL “,” SPHL “,” HLT”.
- PUSH 将两组元数据推入储存箱中
- POP 从暂存箱中取出两组元数据
- XTHL 以缓存器对H和L与储存箱顶两组元交换
XTHL ;动作: (STACK) ←→ (HL) ; 机械周期:5。
- SPHL 将H和L的内容转移给储存箱指针缓存器SP
SPHL ;动作: (SPHL) ←→ (HL) ; 机械周期:1。
- IN 起动输入操作,将8位的数据由特定的输入/输出埠加载累加器
IN 出入埠 ;动作: 地址通径8-15 ← 出入埠
A ←出入端口的资料 ; 机械周期:3
8051是采用MOV指令将输入/输出端口或是缓冲器中的数据取出,如:”MOV A,P1”,”MOV A,SBUF”…等等。
- OUT 起动输出操作,将累加器中8位的数据输出到特定的输入/输出埠。
OUT 出入埠 ;动作:出入端口←地址通径8-15
出入端口的资料←A ; 机械周期:3
8051是采用MOV指令将数据输出到输入/输出埠或是缓冲器中,如:”MOV P1,A”,”MOV SBUF,A”…等等。
- EI 使中断系统致能,机械周期:1。
- DI 使中断系统无能,机械周期:1。
- HLT 暂停,处理机处于呆候状况,机械周期:1。在使用HLT
指令前要使中断系统致能,如果执行HLT指令时,中断系统无能,唯一能使处理机重新起动的是应用重置讯号。一般的8051没有此指令动作,但是如果选择使用CHMOS版本的8051,其功率下降模式指令-“ORL
PCON,#20H”,可以达到相同的效果。
- NOP 无动作
表16. 8085储存箱,输入/输出和机械控制指令目的码和执行周期
|
指令 |
目的码 |
组元 |
时脉周期 |
8085A
机械周期种类 |
|
8080A |
8085A |
| DI |
F3 |
1 |
4 |
4 |
1 |
| EI |
FB |
1 |
4 |
4 |
1 |
| HLT |
76 |
1 |
4 |
4 |
1 |
| IN PORT |
DB YY |
2 |
10 |
10 |
1 3 4 |
| NOP |
00 |
1 |
4 |
4 |
1 |
| OUT PORT |
D3 YY |
2 |
10 |
10 |
1 3 6 |
| POP RP |
11XX0001 |
1 |
10 |
10 |
1 3 3 |
| PUSH RP |
11XX0101 |
1 |
11 |
12 |
2 5 5 |
| SPHL |
F9 |
1 |
5 |
6 |
2 |
| XTHL |
E3 |
1 |
18 |
16 |
1 3 3 5 5 |
(6). 中断指令
RIM :此指令将8位的数据加载累加器,表示串行输入数据与中断情形。
此指令将下列数据加载累加器中:
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
SID |
17 |
16 |
15 |
IE |
7.5 |
6.5 |
5.5 |
位0~2:硬件中断罩除,位内容等于1时罩除。
位3:中断使能旗标,位内容等于1时使能。
位4~6:硬件等候中断,位内容等于1时等候中。
位7:串行输入数据位,位内容等于1时则有。
机械周期:1。
SIM :由累加器的内容来执行以下的功能:设置应体中断RST5.5,
RST6.5和RST7.5的中断罩除位,重置RST7.5的边缘感测输入,输出累加器位7之值给串行输出数据保存器。
机械周期:1。
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
SOD |
SDE |
XXX |
R7.5 |
MSE |
M7.5 |
M6.5 |
M5.5 |
位0~2:分别代表RST5.5,RST6.5,RST7.5罩除位,
若位内容等于1则罩除,等于0则有效。
位3:罩除设置使能,若为0,位0~2被忽略;若为1,罩除位被设置。
位4:重置RST7.5:若为1,RST7.5正反器被重置为0。
位5:没有使用。
位6:若为1,位7输出给串行输出数据保存器。
位7:串行输出数据:若位6等于0则被忽略。
四太空级芯片与一般级芯片的差异
一般我们在地球表面所使用的芯片,由于空间中的幅射粒子很少,所以不必考虑到幅射线的影响。但是高空飞行器如:卫星,航天飞机…等等,它们飞行的高度会受到大量幅幅射线的影响,此时幅射线就会明显的影响芯片的寿命及稳定性。芯片往往会因为承受强烈的粒子轰击,而造成薄膜结构性及电性的破坏,此种破坏称为”幅射性损害”。这些幅射粒子的来源大致可分为下列四种:
- 陷入在 Van Allen 带的电子与质子。
- 陷入在磁气圈的重离子。
- 宇宙射线中的质子与重离子。
- 从太阳焰斑来的质子与重离子。
以上所提的四种幅射粒子来源都会受到太阳活动的影响。在电子学上,幅射破坏可分为两类:一种是总离子幅射量(Total Ionizing
Dose),另一种是单一事件的影响(Single Event
Effects)。总离子幅射量指的是组件长期暴露在离子化幅射下累增的退化影响。而幅射量dose的定义为物质单位质量所受到的幅射能量,单位通常为rads或gray(Gy),1
Gy=100rads,1 rad=6.24×107MeV/g。单一事件的影响指的是单一的离子化粒子,具有足够的能量入射到组件上所产生的影响。不同的入射粒子与组件所产生的单一事件的影响是不同的。而单一事件所产生的影响一般分为两种型态:软件上的错误(soft
errors)与硬件上的错误(hard
errors)。软件上的错误不会对组件产生破坏,它可能造成内存单元或闭锁一个位的改变,或是在输入/输出,逻辑等电路造成变换。而硬件上的错误是指对于组件功能造成永久性的影响,形成对组件本体的破坏。
对于金属氧化半导体而言,再经过幅射后,会造成固定氧化层电荷及接口阻陷浓度的增加。这些放射线离子主要的影响是会产生电子-电洞对穿越氧化层。这些被阻陷的电洞可经由回火来移除。氧化层在长晶的过程中可由经验找出最佳的状况来强化氧化层。其它强化抗幅射影响的制程有利用铝来做防护,阻止从空间来的大部分电子,并且增加MOSFET的起始电压,如此可减低经由放射影响对电压改变的灵敏度。
太空电子学已经发展了好几种不同的电路用来保护与恢复单一事件对集成电路所产生的闭锁。相较之下,太空级的芯片稳定性与使用寿命比一般芯片来的好。例如LPT(Latchup
Protection Technology)电路是被设计用来保护与恢复易受影响的集成电路组件,有下列几种特色:
- 提供组件电流的限制,限制单一事件闭锁(Single Event Latchup)电流。
- 能够在预设的初始值侦测SEL电流的增加,防止毁灭性的故障。
- 当SEL电流超出限制,可以对被保护的组件产生暂时停止运作。
- 组件在暂时停止运作的模式中,能够维持一段预设的时间。
- 在暂时停止运作的模式后,组件能够回归到原来运作的层次。
以HARRIS公司出产的产品为例,如果产品编号末端带有RH字样,就是代表此芯片具有抗幅射的特性。就HS-80C85RH而言,其抗幅射的系数如下:
Parametrics Guaranteed : 1×105 RAD (防护测量的保证值)
Transient Upset > 1×108 RAD/s (防止短暂混乱的上限值)
Latch-up Free > 1×1012 RAD/s (防止闭锁的上限值)
五 程序比较
以下我们以常用的时间延迟为例子,分别以8051与8085来设计0.2秒时间延迟的子程序。
(I). 设8085使用2MHz的时脉频率,其时脉周期为0.5微秒。我们先暂时将子程序写为
DELAY: MVI E,NUMRQ1 ;将需要的数字加载缓存器D与E内
MVI D,NUMRQ2 ;
WAIT: DCR E ;先递减E
JNE WAIT ;若不为0,继续递减
DCR D ;若E降为0,则递减D
JNZ WAIT ;若D不为0,再去递减E
RET ;时间延迟0.2秒后回转
WAIT循环中DCR指令执行需要5个时脉周期,JNZ需要10个时脉周期。每递减一次D,DCR
E指令会执行16×16=256次。所以我们可以利用下面的计算式来计算NUMRQ2和NUMRQ1:
0.2秒=0.2×106微秒
=0.5微秒×[(5+10)+256×(5+10)]×NUMRQ2
+0.5微秒×(5+10)×NUMRQ1
方程式中的两个未知数应该都是整数,我们可先忽略NUMRQ1项,先求得NUMRQ2最接近的整数值,将此值代入NUMRQ2再求得NUMRQ1值,如此可以得到:
NUMRQ1=103=67H
NUMRQ2≒196=C4H
(II). 设8051的石英振荡频率为12MHz,所以一个机械周期(=12个石英振荡周期)为1微秒,我们将子程序写为:
;------------------------------------------------------------------------------------------------
;delay time=R5*(20ms) fXTAL=12MHz
;------------------------------------------------------------------------------------------------
DELAY:
MOV R6,#40 ;共执行(R5)次
DEL:
MOV R7,#249 ;共执行(R6)*(R5)次
$1:
DJNZ R7,$1 ;共执行[(R7)*(R6)]*(R5)次
DJNZ R6,DEL ;共执行(R6)*(R5)次
DJNZ R5,DELAY ;共执行(R5)次
RET ;共执行一次
;------------------------------------------------------------------------------------------------
8051 MOV指令需要1个机械周期,DJNZ指令需要2个机械周期,RET指令需要2个机械周期,所以可算出上面这个子程序的总延迟时间:
T= (R5)*1微秒
+(R6)*(R5)*1微秒
+(R7)*(R6)*(R5)*2微秒
+(R6)*(R5)*2微秒
+(R5)*2微秒
=20043*(R5)微秒+2微秒
现在要求延迟200毫秒,所以可令R5=10,再呼叫DELAY子程序,此时实际的延迟时间为:T=200.432毫秒。
从时间延迟的程序例子来看,8051与8085的程序循环结构类似,但在缓存器的使用上,8085的写法习惯使用缓存器对来处理,好处是在处理某些数据时可同时处理16位的数据;而8051除了能处理16位的数据,在缓存器的使用上弹性较大,没有因为特别的目的而需使用缓存器对的设计。
但在算术运算方面,8051的指令比8085实用很多,最明显的是8051有乘法与除法的指令,而8085却需要写一个子程序来执行乘法与除法,以下我们以乘法6AH×5CH=2618H为例,比较8051与8085:
;----------------------------------------------------------------
;8051的乘法指令写法
;----------------------------------------------------------------
MOV A,#6AH ;A=6AH
MOV B,#5CH ;B=5CH
MUL AB ;6AH×5CH=2618H,故B=26H, A=18H
;----------------------------------------------------------------
;----------------------------------------------------------------
;8085的乘法子程序;当刚始执行MULT1时,各缓存器的内容为:
; A=00000000, B=00000000, C=01011100=5CH, D=01101010=6AH,
; E=00001000, 进位旗标=0
;----------------------------------------------------------------
MULTR: MVI B,00H ;清除代表最后结果的高位部组元为0
MVI E,08H ;装载计数器(两个不带号8位二进制数相乘)
XRA A ;清除进位旗标和累加器A为0
MULT1: MOV A,C ;将乘数载入累加器中
RAR ;把A位值向右移一位,最低位值旋入进位旗标
MOV C,A ;将右旋后的A值存回C
MOV A,B ;将结果的高位部组元转移到A中
JNC MULT2 ;乘数的位值等于0,则跳至MULT2
ADD D ;若乘数的位值等于1,加上被乘数
MULT2: RAR 位部组元值向右移一位 ;将结果的高
MOV B,A ;存回B
DCR E ;降算计数器
RNZ MULT1 ;若不等于0,则跳至MULT1继续运算
MOV A,C ;若等于0,将C的值载入累加器中
RAR ;还需要最后一次旋转的结果
MOV C,A ;将A的值存回C中
RET ;此时低位部组元值才符合正确的乘积
;----------------------------------------------------------------
很显然的可看出在算术运算上,指令的撰写8051比8085好很多。而当指令需要做输入/输出的动作时,会因为所搭配的辅助芯片的不同而有不同的程序写法,8051有32只I/O接脚,8085只有27只I/O接脚,而且8051的输入/输出端口缓存器比8085多,且可视这些输入/输出端口缓存器为数据转移运算的字节,例如在输入按钮状态数据时:
;-----------------------------------------------------------------
(8085) IN 00H ;由输入/输出端口00输入按钮状态数据
;-----------------------------------------------------------------
(8051) WAIT: JB P3.0下,WAIT ;检查在P3.0接脚上的开关是否被按
;-----------------------------------------------------------------
关于硬件接脚上的指令应用8051与8085就有一些差异,当然这也是它们指令语法的特色。
六 结论:
由于8085发展的时间较早,所以在指令的架构会比较原始一点。我们之所以采用8085ISUAL的DPU是8085。从指令的比较结果与CPU读/写的时序图上可看出,8051与是因为8085相似的地方。就现在的实用性而言,8051的芯片与相关书籍易于取得,所以我们有许多会先藉由8051的模拟练习来间接熟悉8085的指令架构。而藉由此比较报告可使对8051熟悉的人员能够很快的学会8085。
|